💡⏳ Mining deep into Data Mining - PART II ⏳💡
Hurray💥 , we have seen the basics of data mining in Part I 😃
Let's get into the phases involved in the KDD process step by step. To start with, let's explore the Data Preprocessing phase.
What actually is DATA in data mining? 🤔
In data mining, Data refers to the collection of objects and their attributes. Umm, Confusing right? 😨
👉 An Object is just like an entry in a table or an instance. It is also known as record, point, entity or sample.
👉 Attribute is any property or characteristic of an object.
👉 For example, If the eye of a person is considered as an object then, the eye color, blink rate are regarded as the attributes.
👉 Attribute can also be called a feature, field, characteristic, or variable in data mining.
👉 Here, the organization of data is in a tabular form.
Let's get more technical 💻🙌
👉 Each of the rows can be called vectors, (ie) object vectors or feature vectors.
👉 The number of attributes will determine the dimensions of the vector.
👉 Thus, our data will be a collection of N-dimensional vectors.
👉 Let's understand with an example
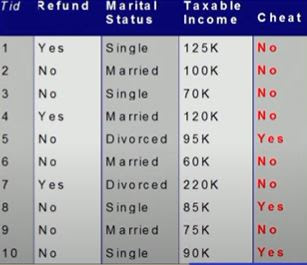
The above table denotes fraudulent loan transaction details. Each of the rows or entities can be called a vector. The attributes such as Tid, Refund, Marital status, Taxable income determine the dimensions (ie) according to the given example, each of the vectors is three-dimensional. The target attribute is Cheat.
Attributes, properties and their types ✊ :
As discussed already, the attribute is any characteristic or feature of an object.
The type of attribute depends on the properties it possesses:
👉 Distinctness - equal or not equal (=,!=)
👉 Order - Greater than or less than (< >)
👉 Addition, subtraction (+, -)
👉 Multiplication, division (*, /)
The different types of attributes include
👉 Nominal - any unique value of an object such as ID, eye colour, country zip code
Property: Distinctness - since it is a static value, only equality can be checked
Operations: mode, entropy, correlation, chi-square test
👉 Ordinal - based on rankings (eg: ratings from1 to 5, preferences)
Property: Distinctness, Order - since it is based on hierarchy, the data can be ranked as most and least
Operations: median, rank correlation, sign tests
👉 Interval - Calendar dates, Temperature in Celcius or Kelvin.
Property: Distinctness, Order, Addition/Subtraction - intervals can grow by adding
Operations: Mean, standard deviation, t, and F tests
👉 Ratio - Interval, count and time, length
Property: Distinctness, Order, Addition/Subtraction, Multiplication/Division - for example, we can divide a length by another length but cannot be done for a date value.
Operations: Geometric mean, harmonic mean, percent variation
The ratio attribute can be divided into Discrete or Continuous values
👉 Discrete Attribute
➡ Has finite or countably infinite values
➡ Generally represented as integer values
➡ Example, zip codes, count of words in a document, number of states in the country.
👉 Continuous Attribute
➡ Has real numbers as attribute values
➡ Generally represented as floating-point values
➡ Example, height, weight, temperature or air quality metrics
Types of Data sets other than table format 😃:
👉 Graph data - social network data, molecular structure, World wide web
👉 Ordered data - spatial(geographical or map data), sequential (makes sense when viewed as a linear data - speech, or sound, genome sequence), temporal (based on events)
What should we do before data pre-processing? 🤔
👉 Determine the data quality. Some factors that affect the data quality are
👉 Noise - inconsistent data
👉 Outliers - data that does not belong to the common characteristics or pattern
👉 Missing values - Replace with probability values or estimate and eliminate them
👉 Duplicate data - Perform data cleaning
Data pre-processing techniques 💭
👉Aggregation
➡ Combining two or more attributes or objects as a single entity
➡ The main purpose is to reduce the data points, obtain more stable data, and change of scale of data (eg) cities can be aggregated into regions, states, etc
👉Sampling
➡ Sampling is basically the process of data selection and obtaining a sample of data
➡ Choose a representative sample so that it is effective
Types of sampling
➡ Simple Random Sampling: the equal probability of selecting an item
➡ Sampling with replacement: Remove the sample from the entire sample
➡ Sampling without replacement: objects are not removed from the whole data
➡ Stratified sampling: Split the data into partitions and draw random samples from them
👉Dimensionality Reduction
➡ Higher the dimensions of data more will be the complexity of analysis
➡ Techniques involved are:
➡ PCA (Principal Component Analysis)
➡ Singular value decomposition
➡ Supervised and unsupervised techniques
👉Feature subset selection
➡ Redundant features are the ones that are commonly found in many object entries with high influence. Example: The salary of an employee and tax paid
➡ Irrelevant features include student's date of birth for CGPA calculation
➡ Techniques involved are:
➡ Brute force approach
➡ Embedded approach
➡ Filter approach
➡ Wrapper approach
👉Feature creation
➡ Create new attributes from the existing original attributes
➡ One technique is Data Discretization - converting and defining discrete data into continuous intervals.
👉Attribute transformation
➡ Any function that maps the set of input values to obtain with a new set of replacement values where the new values are identified by the old ones
➡ Example: Normalization, Standardization
We are done with a basic understanding of data pre-processing. Let's get more mathematical 💥😃 in the upcoming posts



Nice work! Keep enlightening!!
ReplyDelete